文章相似度計算-可用於文件推薦系統
這篇分享文件相似度的計算邏輯,提供一個方法算出文章之間的相似度,可以應用在推薦系統上,幫助使用者找到類似的文件等。
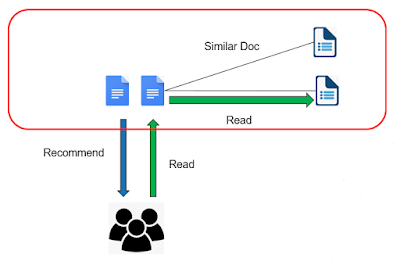


 每一篇文章可以跟過濾後的詞去算tfidf,因此每篇文章就可以得到一組向量值。
每一篇文章可以跟過濾後的詞去算tfidf,因此每篇文章就可以得到一組向量值。


如上圖所示,文件要如何推薦給使用者有很多方法,有空再分享,今天要講的是紅色框框部份,文件之間要如何是計算相似度。

原始文章,也就是彼此之間要算相似度的文章,拿來做斷詞。網路有很多種斷詞器,本人是用結巴斷詞。

再來做過濾把一些雜訊過濾掉,可用的有字數過濾、詞性過濾等等,接下來的詞去重複後就可以做VSM(圖片做錯)了。


接下來將文章間的向量去算餘弦相似度,每篇文章跟其他文章間就可以得到相似值了,那判斷相似的方法可以設個門檻值或找前幾高的文章當作相似都是可行的方法。
這篇介紹了一個簡單的計算方法,主要介紹整個邏輯,詳細的參數設定以及過濾方法等,可能會因為文章特性而不一樣,要有好的推薦效果還需要後續的驗證機制。
留言
張貼留言