Machine Learning-python用LSTM模型進行時間序列預測1(LSTM to do time series forecasting using python keras)
這篇實作LSTM多對一的模型,顧名思義就是用過去多筆資料去預測未來一筆。
整個處理流程可分為
1.讀取資料
2.正規化資料(較會收斂)
3.切割訓練集
4.打亂資料順序(訓練結果可更好)
5.建模型
6.最佳化並評估訓練結果
以下直接用程式範例說明
import pandas as pd
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten, LSTM, TimeDistributed, RepeatVector
import mysql.connector
from keras import optimizers
from keras.callbacks import EarlyStopping
#讀資料
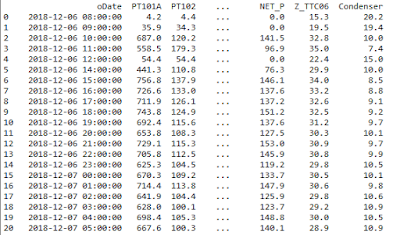
xls_file = pd.ExcelFile('A.xlsx')
df = xls_file.parse('sheet1')
data=df
#正規化
def normalize(train):
train_norm = train.apply(lambda x: (x - np.mean(x)) / (np.max(x) - np.min(x)))
return train_norm
data=normalize(data)
#切訓練集,24筆去預測未來1筆,Y_train就是你要預測的參數。
def buildTrain(train, pastDay, futureDay):
X_train, Y_train = [], []
for i in range(train.shape[0]-futureDay-pastDay):
X_train.append(np.array(train.iloc[i:i+pastDay]))
Y_train.append(np.array(train.iloc[i+pastDay:i+pastDay+futureDay]["goal"]))
return np.array(X_train), np.array(Y_train)
X_train, Y_train = buildTrain(data, 24, 1)
#打亂資料時間順序
def shuffle(X,Y):
np.random.seed(10)
randomList = np.arange(X.shape[0])
np.random.shuffle(randomList)
return X[randomList], Y[randomList]
X_train, Y_train=shuffle(X_train, Y_train)
#建立LSTM模型,這邊建兩層並用Dropout避免overfit最後用tanh當激活函數,用linear也行。
def buildManyToManyModel(shape):
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(shape[1],1),input_dim=shape[2]))
model.add(Dropout(0.2))
model.add(LSTM(100, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(1, activation = "tanh"))
adam=optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(loss='mse', optimizer=adam)
model.summary()
return model
model = buildManyToManyModel(X_train.shape)
#設early_stopping,並切驗證集,最後儲存模型。
early_stopping = EarlyStopping(monitor='val_loss', patience=50, verbose=2)
model.fit(X_train, Y_train, epochs=5000, batch_size=128, validation_split=0.33, callbacks=[early_stopping])
model.save('LSTM_time_series.h5')
相關更深入寫法可以參考這本書:Deep learning 深度學習必讀
整個處理流程可分為
1.讀取資料
2.正規化資料(較會收斂)
3.切割訓練集
4.打亂資料順序(訓練結果可更好)
5.建模型
6.最佳化並評估訓練結果
以下直接用程式範例說明
import pandas as pd
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten, LSTM, TimeDistributed, RepeatVector
import mysql.connector
from keras import optimizers
from keras.callbacks import EarlyStopping
#讀資料
xls_file = pd.ExcelFile('A.xlsx')
df = xls_file.parse('sheet1')
data=df
#正規化
def normalize(train):
train_norm = train.apply(lambda x: (x - np.mean(x)) / (np.max(x) - np.min(x)))
return train_norm
data=normalize(data)
#切訓練集,24筆去預測未來1筆,Y_train就是你要預測的參數。
def buildTrain(train, pastDay, futureDay):
X_train, Y_train = [], []
for i in range(train.shape[0]-futureDay-pastDay):
X_train.append(np.array(train.iloc[i:i+pastDay]))
Y_train.append(np.array(train.iloc[i+pastDay:i+pastDay+futureDay]["goal"]))
return np.array(X_train), np.array(Y_train)
X_train, Y_train = buildTrain(data, 24, 1)
#打亂資料時間順序
def shuffle(X,Y):
np.random.seed(10)
randomList = np.arange(X.shape[0])
np.random.shuffle(randomList)
return X[randomList], Y[randomList]
X_train, Y_train=shuffle(X_train, Y_train)
#建立LSTM模型,這邊建兩層並用Dropout避免overfit最後用tanh當激活函數,用linear也行。
def buildManyToManyModel(shape):
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(shape[1],1),input_dim=shape[2]))
model.add(Dropout(0.2))
model.add(LSTM(100, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(1, activation = "tanh"))
adam=optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(loss='mse', optimizer=adam)
model.summary()
return model
model = buildManyToManyModel(X_train.shape)
#設early_stopping,並切驗證集,最後儲存模型。
early_stopping = EarlyStopping(monitor='val_loss', patience=50, verbose=2)
model.fit(X_train, Y_train, epochs=5000, batch_size=128, validation_split=0.33, callbacks=[early_stopping])
model.save('LSTM_time_series.h5')
相關更深入寫法可以參考這本書:Deep learning 深度學習必讀
留言
張貼留言